Jean-Baptiste Kempf : « Souveraineté, ça rappelle le suzerain et les serfs »

On ne le présente plus. Il a co-créé VLC, le logiciel français le plus utilisé au monde. Il est directeur technique de Scaleway. Il a fondé Kyber, une infrastructure réseau et vidéo conçue pour le contrôle de machines à distance en temps réel, et Playruo, une plateforme de cloud gaming. Il trouve encore le temps de donner des conférences et de co-animer le podcast À la French. Invité de ma Matinale Tech du 22 mai, Jean-Baptiste Kempf a balayé les gros sujets du moment avec ce franc-parler qui le caractérise : Cloud souverain, pénurie de RAM, IA en local, AI-assitant coding. Retour sur son interview, et place à la magie.
S’abonner à la chaîne Twitch
Resumulus : les 3 phrases de JB Kempf à retenir
- « Souveraineté, ça rappelle le suzerain et les serfs. Ce qui est important à comprendre, c’est la notion d’autonomie. »
- « Ton Claude, c’est un stagiaire ou un junior qui n’a qu’une seule envie, aller prendre sa bière. Alors lui, ce n’est pas d’aller prendre sa bière, c’est de consommer le moins de tokens. »
- « Un SSH ça ne s’arrête pas aux frontières. La question, c’est qui root sur ta machine. »
Alors que la crise de la RAM ne semble pas faiblir, Jean-Baptiste confie à mon micro qu’il l’avait vu venir. « Je l’avais prédit il y a un an, je ne suis pas très étonné. J’ai acheté pas mal de matos justement il y a un an parce que je savais ce qui allait arriver. »
Pour rappel, depuis fin 2025, les prix de la RAM explosent. En cause : une demande tirée par l’IA, première consommatrice de mémoire du moment. Le problème ? Trois entreprises au monde fabriquent de la RAM : Samsung, TSMC et Intel, et elles peinent à suivre le rythme. « Construire une usine de RAM c’est très long, et construire une usine de CPU c’est même pire, quasiment personne ne sait faire ça », prévient Jean-Baptiste.
Ceux qui espèrent que les éditeurs de logiciels vont se remettre à coder frugalement pour compenser ont du souci à se faire. « Non, ça, ça ne va pas arriver. Avec Electron, il faut 4 gigas de RAM juste pour avoir un lecteur de musique. » Des géants comme Spotify ou Teams sont des monstres de RAM pour des usages qu’on réalisait autrefois avec un centième des ressources. La raison est simple : il est plus rapide et moins cher de développer en JavaScript et HTML qu’en natif optimisé.
Tout recoder en Rust grâce à l’IA ?
Ce langage qui fête sa première décennie gagne un regain d’intérêt dans la communauté tech, notamment pour son profil écologique. Il consomme sensiblement moins d’énergie que Java, JavaScript ou Python. Il existe même un thread Reddit où certains débattent sérieusement de réécrire Kubernetes en Rust, une blague au départ, qui finit par soulever de vraies questions. Toutefois, Kempf tempère l’enthousiasme : « Tu pourrais le faire en Rust, mais il faut avoir des toolkits graphiques en Rust, tu n’en as pas. Tu en as quelques-uns, mais pour moi ce n’est pas encore au niveau. »
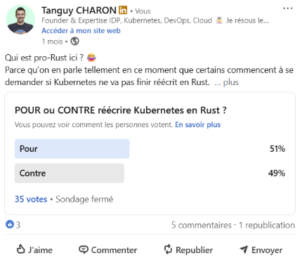
22 avril 2026. Le résultat est serré.

C’est évidemment la question que je ne pouvais omettre de poser à Jean-Baptiste Kempf. Il me répond très honnêtement : « C’est une bonne question parce que moi je déteste ce mot. Souveraineté, ça rappelle le suzerain et les serfs. Ce n’est pas le bon terme, mais c’est le terme que tout le monde utilise, donc on va continuer à l’utiliser. »
Il préfère parler d’autonomie. Et pour situer le contexte, il me livre une analogie simple « L’informatique, c’est quand même le seul endroit où tu es hyper fier d’avoir fait un ‘move to cloud’ et d’avoir tout mis chez GCP ou chez Azure. Maintenant tu vas voir quelqu’un qui fabrique des voitures, tu dis ‘j’ai qu’un seul fournisseur’, on te dit ‘mais tu es complètement fou’, parce que quand tu as qu’un seul fournisseur, le fournisseur augmente tes prix et tu ne peux rien faire. »
CTO d’un des principaux Clouds souverains européens, Jean-Baptiste Kempf connaît bien le sujet. Et même si on voit aujourd’hui fleurir de nouveaux acteurs de la souveraineté en France, côté IA, Cloud ou hardware comme Vsora ou Luchrome qui nous rendent fiers sur la scène internationale, pour lui, il reste trois problèmes structurels à adresser.
Le lock-in fournisseur à la base de la pression tarifaire
Le premier problème de la souveraineté est tarifaire. VMware, Citrix, Google BigQuery, Azure avec Copilot, la liste de ceux qui ont battu le fer tant qu’il était chaud sur leurs clients captifs s’allonge chaque trimestre. « Ils augmentent les prix, tu ne peux rien faire, tu es tellement lock-in. » C’est la mécanique du fournisseur unique : un luxe qu’aucun directeur des achats industriel ne s’autoriserait, mais qui, dans l’informatique, est encore monnaie courante.
FISA 702, National Letter, Cloud Act : la bombe à retardement sécuritaire
Le deuxième problème est quant à lui sécuritaire. Post-Snowden, les Américains ont espionné Angela Merkel alors qu’elle était chancelière. Les géants économiques français ne sont pas à l’abri. Pour Jean-Baptiste Kempf, l’argument « je n’ai rien à cacher » ne tient pas : « Tu as toujours quelque chose à cacher. Et si toi tu n’as rien à cacher, il y a quelqu’un autour de toi qui a quelque chose à cacher. »
Et derrière l’argument sécuritaire, il y a une mécanique légale encore bien trop méconnue.
Le Patriot Act, voté après le 11 septembre, a donné aux agences américaines des pouvoirs de surveillance étendus sur les communications numériques. Quant à la loi FISA, en particulier la section 702, elle autorise la collecte de données sur des non-citoyens américains, sans mandat individuel. Le Cloud Act, lui, oblige les entreprises américaines à fournir des données stockées n’importe où dans le monde si une juridiction américaine le demande. Peu importe que vos serveurs soient à Paris.
Parmi tous ces dispositifs, Jean-Baptiste Kempf attire notre attention sur les National Security Letters. Ces ordonnances secrètes, assorties d’une interdiction absolue d’en parler sous peine de sanctions pénales, peuvent cibler aussi bien une entreprise qu’un individu.
« Avec FISA 702 et les National Security Letters, une agence à 3 lettres américaine peut aller voir un DevOps et lui dire ‘j’ai besoin des données de cette entreprise. […] La National Security Letter fait que tu n’as pas le droit de résister, et surtout tu n’as pas le droit d’en parler à ton entreprise. »
Jean-Baptiste Kempf
Et le fournisseur cloud peut répondre honnêtement qu’il n’a reçu aucune requête gouvernementale, parce que la requête a été adressée à une personne physique, sans trace officielle. Dans cette culture du secret d’État et de la porosité entre la tech et le renseignement américain, la frontière entre contrainte légale et recrutement informel est floue.
S’il existe bien un accord censé encadrer les transferts de données entre l’Europe et les États-Unis, le Data Privacy Framework, adopté en 2023 en remplacement du Privacy Shield invalidé par la CJUE, il ne s’applique qu’aux entreprises. Les National Security Letters, elles, s’appliquent aux individus.
Des États-Unis qui s’enrichissent, une Europe qui s’appauvrit
Le troisième problème est simple : chaque euro dépensé chez un hyperscaler américain sort du circuit économique européen pour enrichir nos confrères d’Outre-Atlantique. Pour Jean-Baptiste Kempf, c’est aussi une question de moralité : « À un moment, il faut se dire : si je veux garder le fait que c’est agréable de vivre en France, il faut aussi réinjecter de l’argent dans l’économie, surtout dans la tech parce que c’est là où il y a le plus de marge. »
Un manque d’investissement européen ?
Quand j’interroge Jean-Baptiste Kempf sur les propos prononcés par Arthur Mensch à l’Assemblée nationale : « aujourd’hui j’ai besoin de 10 milliards pour construire l’infrastructure pour faire tourner mes modèles. Le problème c’est qu’on a oublié de faire un fonds de pension qui nous permette aujourd’hui d’investir autant d’argent sur le très long terme », sa réponse est nuancée.
Sur le sous-investissement, il est d’accord : l’absence de capitalisation dans notre système de retraite prive l’écosystème des fonds qui alimentent les séries B, C, D aux États-Unis et en Norvège. Mais il rappelle que ce qui coûte vraiment cher dans l’IA, ce sont les puces, pas les datacenters, qui restent finançables. Et c’est là que l’Europe est vraiment à la traîne : le design de chips d’inférence.
Avant de répondre, mettons-nous d’accord sur les termes. Un Cloud souverain, au sens strict, c’est un Cloud juridiquement hors de portée du Cloud Act américain. Ce qui exclut par nature des acteurs comme Bleu (Orange, Capgemini, Microsoft) ou S3ns (Thales, Google) : bien qu’ils bénéficient de la mention « cloud de confiance » et que S3ns ait récemment décroché la certification SecNumCloud. Si l’un des fournisseurs relève du droit américain, les données peuvent être légalement consultées par les autorités US.
Jean-Baptiste Kempf est plus dur encore. Pour lui, ces acteurs « font exactement l’inverse des 3 critères de souveraineté : l’argent repart aux États-Unis, tout est backdooré, et tu continues à rester chez le même fournisseur. Le jour où Google dit à Bleu ‘ça va coûter plus cher’, tu vas faire quoi ? La question, c’est qui root sur ta machine. »
Précision faite, où en sont nos vrais champions souverains ? Jean-Baptiste Kempf leur avait attribué la note de 7/10 lors de la Grosse Conf en avril dernier. Une note en progression : « aujourd’hui, tu as quasiment tous les services. » Clever Cloud, Cloud Temple, Outscale, Scaleway, OVH se sont retroussés les manches. « Ce qui manque, c’est du scale ». Les Clouds français ont comblé l’écart fonctionnel, il leur reste à combler l’écart d’échelle.
Être souverain oui, mais ne pas contester les standards
Quand j’émets l’idée que « suivre l’API d’AWS », c’est accepter qu’un géant plus grand dicte les règles, Jean-Baptiste Kempf ne me contredit pas, mais il temporise : « Il y a des choses qui ont été standardisées. Le stockage objet c’est S3. Pareil pour Kubernetes. » Les contester est une perte d’énergie. La bonne stratégie : accepter ces standards et construire dessus, même s’ils ont été imposés par des géants américains. En revanche, là où aucun standard ne s’est imposé, réseau, VPC, VPN, le débat a du sens et l’innovation reste possible.

« Je suis contre le vibe-coding, je suis pour le AI assistant coding », me répond Jean-Baptiste Kempf quand je mentionne le sujet de l’IA. « Ton Claude, c’est un stagiaire ou un junior qui n’a qu’une seule envie, c’est d’aller prendre sa bière. Alors lui, ce n’est pas d’aller prendre sa bière, c’est de consommer le moins de tokens. Tu lui demandes une tâche, il va trouver la façon la plus simple de la faire. Si tu lui donnes plus de contraintes, il va aller matcher tes contraintes, toujours en faisant le truc le plus simple. »
Le stagiaire, donc. Brillant, rapide, enthousiaste. Mais laissez-le sans cadre et dans trois mois, le code est imbitable. Donnez-lui un scope précis, des contraintes claires, une responsabilité unique, et il fait des miracles. C’est ça, la méthode Kempf : des composants. Pas des microservices, qu’il décrit comme « une mauvaise idée en général », mais un découpage fonctionnel propre. Un package pour la gestion des utilisateurs, un autre pour la liste, un autre pour l’édition. Chaque composant a une surface de contexte réduite, peut être confié au modèle sans lui faire ingérer tout le repo, et se refactore sans tout casser. « Si tu as bien scopé, tu bosses que là-dessus, et ça fait des miracles. »
Ce n’est pas qu’une question de qualité de code. Les infrastructures saturent sous le trafic de l’IA générative, massif, asymétrique. Les outils réseau traditionnels beuguent parce qu’ils comptent des requêtes au lieu de mesurer des tokens et la charge GPU réelle. Un problème que l’on observe aussi bien chez Claude Code que chez Codex, et que les nouvelles approches d’AI Gateway sur Kubernetes commencent tout juste à adresser.
L’IA en local, un tournant obligatoire ?
Rares sont celles et ceux qui ont franchi le pas. Pourtant JB Kempf est catégorique : c’est inévitable pour des raisons de confidentialité, d’écologie, de coût ou de transfert de données. Mais dans un futur proche, à quoi ça va ressembler ? Selon Jean-Baptiste Kempf, à un Claude Code modifié pour pointer sur son propre modèle. La couche applicative reste, mais la dépendance au provider disparaît.
Avant Kyber, avant Scaleway, avant tout, il y a VLC. Ce lecteur multimédia open source qui tourne sur des centaines de millions de machines dans le monde. Le fun fact, VLC aurait été créé à la base pour jouer à Doom en réseau. Jean-Baptiste Kempf s’en dédouane, mais ne dément pas la rumeur 👇

Depuis, la carrière s’est bien épaissie. Il rejoint Scaleway en 2023 comme CTO, fonde Playruo, une plateforme de cloud gaming et Kyber.
Kyber, c’est une infrastructure réseau et vidéo conçue pour le contrôle de machines à distance en temps réel. Le SDK de Kyber est capable d’ingérer n’importe quel type de capteur, vidéo, audio, GPS, LiDAR, télémétrie IoT, sous-titres, et de le renvoyer vers n’importe quelle interface : écran, casque VR, gamepad, application industrielle.
« On a un prototype avec une aile volante, un drone, un aspirateur, un petit rover avec un bras télescopique, et on est en train de regarder comment contrôler un bateau à distance. L’idée c’est de montrer qu’on est capables de contrôler n’importe quel type de machine. »
En bonne voie puisque l’entreprise vient tout juste de lever 5 millions de dollars pour accompagner sa montée en puissance. Une info que Jean-Baptiste n’a pas manqué de nous livrer en avant-première pendant la Matinale.
Des années après VLC, Jean-Baptiste Kempf construit toujours des infrastructures pour que les machines se parlent.
Voilà pour cette interview.
Si vous être team mémoire visuelle, je vous laisse le best-of :
La version intégrale de la matinale tech est disponible ici.
Merci Jean-Baptiste.
Pour ma part, je suis en live tous les vendredis, de 09h à 10h, sur Twitch, LinkedIn et YouTube.
Au programme, toujours de l’actu tech & des invités. Abonnez-vous pour ne pas louper les prochaines.
Et rappelez-vous, « la question, c’est qui root sur ta machine. »
Méfait accompli.
À explorer dans le grimoire

Scaleway, OVHcloud… Le Cloud souverain français est-il une alternative crédible aux géants américains ?


Souveraineté numérique : quels outils français en alternatives aux GAFAM ?
