Codex VS Claude Code : faut-il vraiment choisir sa team ?

“T’es plutôt Codex ou Claude Code ?” Quand j’entends cette question, je ressens la même énergie que “T’as choisi Bulbizarre ou Salamèche ?”
Si t’es team Salamèche, tu le restes. Sinon tu recommences la partie.
Codex, Claude Code, Copilot ou les IA intégrées aux IDE comme le font Cursor ou Windsurf. Le choix ne manque pas. Pourtant, deux noms, indissociables de l’imaginaire collectif des LLMs ont pris une longueur d’avance : Anthropic et Open AI. Côté agents de coding, leurs poulains Codex et Claude Code se hissent en tête des outils les plus plébiscités par les tech, comme les non-tech savy.
Faut-il vraiment choisir sa team ? Sont-ils si différents ? Qui tient le haut du pavé ? J’ai passé les deux outils au crible pour vous livrer un comparatif honnête. Par contre, je préviens : j’ai ma petite préférence.
Place à la magie.

Resumulus : les 3 points à retenir de l’article
- Claude Code excelle sur le code complexe, Codex sur l’autonomie système.
- Claude Code coûte cher en tokens et peut freeze. Codex manque de transparence sur sa consommation et souffre d’amnésie sur les longues sessions.
- Utilisez les deux en parallèle. Et n’oubliez pas : les modèles d’IA prennent toujours le raccourci qui consomme le moins de tokens. C’est à vous de relire.
Pas de David quand on compare Codex à Claude Code Code.
Les deux sont des Goliaths.
Codex est un produit d’OpenAI, l’entreprise qui a fait basculer l’humanité dans l’ère de l’intelligence artificielle grand public.
Claude Code, lui, est l’agent de coding IA d’Anthropic, l’acteur qui signe aujourd’hui la plus belle percée du secteur.
La firme américaine entre tout juste en bourse et sa valorisation dépasse déjà celle d’Open AI, avec une récente levée de fond de 65 milliards, pas plus tard que le 28 mai dernier. Ironique, quand on sait qu’Anthropic a été fondée par la fratrie Amodei, des dissidents d’OpenAI partis par peur de la dérive trop commerciale de Sam Altman.

Le combat est tout sauf déséquilibré.
Avant de rentrer dans les détails, une petite rétrospective s’impose.
Codex, l’agent IA qui n’a pas besoin de personne
À l’origine, Codex est le nom donné en 2021 à un modèle de langage spécialisé dans le code. Entraîné sur des milliards de lignes de code public (notamment issus de GitHub), c’est ce modèle initial qui a servi de moteur pour lancer la toute première version de GitHub Copilot.
Enterré en 2023, il a été ressuscité deux ans plus tard sous la forme d’un agent autonome multi-tâche, propulsé par GPT-5.5, accessible en application desktop (macOS/Windows), en CLI et en extensions. Le Codex d’aujourd’hui n’a plus grand-chose à voir avec celui d’antan.
💡 Fun fact : son nom de projet secret en interne était WHAM (et non pas Wham!). Un nom court, choisi pour que l’IA puisse retrouver instantanément ses propres fichiers dans sa base de code, sans confondre le terme avec un autre mot du dictionnaire.
Sa philosophie : la délégation asynchrone.
Vous lui confiez une tâche. Il crée des branches en arrière-plan, lance plusieurs agents en parallèle sur des worktrees isolés, et vous renvoie le résultat pendant que vous faites autre chose.
⚠️À noter : depuis quelques semaines, Claude Code propose des fonctionnalités similaires de travail en arrière-plan. Ce qui tendait à être une spécificité forte de Codex l’est de moins en moins.
Claude Code, la vache à lait d’Anthropic
Côté Anthropic, Claude Code est devenu une véritable poule aux œufs d’or. Né en 2025, il tourne sur le tout dernier modèle Claude Opus 4.8 depuis le 28 mai dernier. En moins d’un an, Claude Code a franchi le milliard de dollars de run rate annualisé, devançant la vitesse d’adoption initiale de ChatGPT lui-même. Il a progressivement remplacé ChatGPT et consorts dans les recommandations d’outils IA qui fleurissent sur LinkedIn, au point de devenir la référence par défaut dans les conversations tech.
💡 Fun fact : Claude Code rédige à lui seul 4 % de tous les commits publics sur GitHub, et SemiAnalysis projette 20 % d’ici fin 2026. Pendant que vous lisez ces lignes, il est sûrement en train de coder. À moins qu’il ne lise ces lignes pour vous.
Sa philosophie : la collaboration en direct.
Il vit dans votre terminal. Il tape des commandes sous vos yeux. Il explique ce qu’il fait, demande confirmation avant de lancer quoi que ce soit de potentiellement destructeur. Ah aussi, il écrit des petits fichiers de notes secrets dans votre projet (des .claude_memory) pour se souvenir de ses choix d’architecture d’une session à l’autre.
⚠️ Pensez à cleaner régulièrement la mémoire et le contexte de Claude Code. Plus vous accumulez d’historique sans le purger, plus vous augmentez l’entropie de votre session et ça se ressent sur la qualité des réponses.
Pour comparer l’efficacité et la pertinence des outils de coding, il existe des tests de référence reconnus par la communauté. Ce qui est intéressant dans cette démarche, c’est de soumettre les deux outils aux mêmes cas d’usage pour faire ressortir les forces et les faiblesses de chacun.
Ce qui suit reprend les conclusions de cette analyse comparative GPT-5.5 vs Claude Opus 4.7 publiée en avril 2026, qui s’appuie sur six benchmarks officiels. C’est à ce jour la comparaison la plus complète que j’ai pu lire sur le sujet. Claude Opus 4.8 étant encore tout récent, cet article sera mis à jour à mesure que les données arrivent.
SWE-bench Verified : résoudre de vrais bugs GitHub
Le SWE-bench est pour beaucoup le test de référence. Le principe : on soumet à l’agent un vrai bug issu d’un projet open-source GitHub, avec l’historique du ticket, les fichiers concernés et les tests existants. L’agent doit localiser le problème, modifier le code et faire passer les tests, de bout en bout, sans aucune intervention humaine.
En 2024, les meilleures IA stagnaient sous les 15-20 %. Aujourd’hui, Claude Code (Opus 4.7) culmine à 87,6 % de réussite contre 84,2 % pour Codex (GPT-5.5). Entre Opus 4.6 et 4.7, Anthropic a gagné 10,9 points de pourcentage en une seule itération. C’est parlant.
À noter toutefois : en février 2026, OpenAI a annoncé qu’ils ne rapporteraient plus leurs scores sur ce benchmark. Les arguments qu’ils avancent : contamination des données d’entraînement (les dépôts open-source du benchmark sont souvent utilisés pour entraîner les modèles), et qualité des tests jugée insuffisante (59,4 % des problèmes audités contiendraient des erreurs de conception qui invalident des solutions pourtant correctes). Ils recommandent de se référer au SWE-bench Pro. Ça tombe bien, c’est justement le test suivant.
SWE-bench Pro : le même test, mais à une toute autre échelle
Même logique que le SWE-bench Verified, mais les bugs proviennent cette fois de bases de code massives, multi-fichiers, avec des dépendances enchevêtrées entre plusieurs modules.
L’agent ne peut plus se contenter de lire deux fichiers et de patcher une fonction : il doit comprendre l’architecture globale du projet avant de toucher quoi que ce soit.
Exemple fictif : un bug fait planter les commandes après 23h. En apparence, un problème de timezone, en réalité, un conflit entre le service d’auth (UTC) et le module de paiement (heure locale). L’agent doit toucher 4 fichiers dans 3 modules. S’il patche au mauvais endroit, les tests passent mais le bug revient en prod. On évalue la capacité de l’agent à comprendre les dépendances, pas juste corriger.
Le modèle Opus 4.7, utilisé jusqu’en mai dernier sur Claude Code affiche 64,3 % contre 58,6 % pour le modèle GPT 5.5 de Codex. Concrètement, ça signifie que sur 100 bugs issus d’une grosse base de code, Claude Code en résout 6 de plus. Ce n’est pas spectaculaire, mais ça conforte Claude Code dans sa longueur d’avance sur des projets complexes.
Terminal-Bench 2.0 : le test de survie dans un terminal
L’objectif de ce test est de mesurer la capacité d’un agent à opérer dans un environnement système réel. Exécuter des commandes Bash, installer des dépendances, compiler des projets, lancer des scripts de tests, coordonner plusieurs outils en séquence, et gérer les erreurs qui remontent dans la console. En clair : est-ce que l’agent sait se débrouiller seul dans un terminal ?
Ça me rappelle un film.

Exemple fictif : l’agent doit faire tourner une suite de tests sur un projet Node.js. Il installe les dépendances, lit les erreurs, corrige ce qui bloque, relance. Il n’a pas d’instructions, juste un objectif finale.
Sur ce test, Codex décroche 82,7 %, contre 69,4 % pour Claude Code, soit 13 points d’écart. Codex excelle dans la sélection précise d’outils, gère les tâches multi-étapes avec plus de consistance, et récupère mieux sur les erreurs.
Le retard de Claude Code s’explique par un choix architectural : Anthropic lui impose des barrières de sécurité strictes qui l’empêchent d’exécuter des commandes jugées potentiellement dangereuses sur votre machine. C’est assumé, mais ça bride les capacités de l’agent sur ce terrain.
Expert-SWE : les tâches de longue haleine
Ce benchmark teste la capacité d’un agent à tenir sur des tâches de programmation longue portée, l’équivalent de 20 heures de travail humain en médiane. Un vrai chantier de développement à mener de bout en bout. Codex affiche 73,1 %. Claude Code n’a pas encore de score officiel publié sur ce test.
OSWorld-Verified : piloter un environnement desktop
OSWorld-Verified mesure la capacité d’un agent à interagir avec un environnement desktop complet : naviguer dans des applications, manipuler des fichiers, exécuter des tâches sur une interface graphique réelle. C’est le terrain de jeu de l’agent bureautique plus que du coding pur. Les deux modèles sont au coude à coude : Codex à 78,7 %, Claude Code à 78,0 %. Un écart de 0,7 point qui ne permet pas de départager les deux.
MRCR v2 : retrouver une aiguille dans une botte de foin
Le MRCR v2 mesure la capacité d’un modèle à retrouver des informations précises dans des contextes très longs, entre 512K et 1M de tokens. En pratique : est-ce que l’agent se souvient d’un détail mentionné il y a 800 000 tokens ? C’est le scénario du monorepo complet chargé en contexte, ou de la longue session de refactoring qui s’étire sur des heures.
Et là, l’écart est significatif. Codex affiche 74 % contre 32,2 % pour Claude Code, soit 41 points d’écart. Concrètement : si vous chargez un monorepo complet en contexte et que vous demandez à l’agent de retrouver une information mentionnée 800 000 tokens plus tôt, Codex y arrive deux fois plus souvent que Claude Code.
Ce que ça dit sur les styles de travail des deux agents
Au-delà des scores, cette analyse fait ressortir deux philosophies de résolution distinctes. Codex privilégie la concision : quand il corrige un bug, il génère un correctif serré, avec un minimum de commentaires. Il va droit au but. Claude Code est plus verbeux : en plus du correctif, il détaille les raisons du bug, suggère du refactoring et émet des alertes sur d’autres pans liés de la base de code.
Chiffre à l’appui, GPT-5.5 utilise 72 % de tokens de sortie en moins que Claude Opus 4.7 pour accomplir des tâches de programmation équivalentes. Un écart qui a un impact financier direct sur les boucles agentiques à fort volume de requêtes, et qui explique en partie pourquoi Codex peut paraître plus « efficace » à l’usage intensif, même quand Claude Code produit un travail plus documenté.
Tableau récapitulatif des benchmarks :
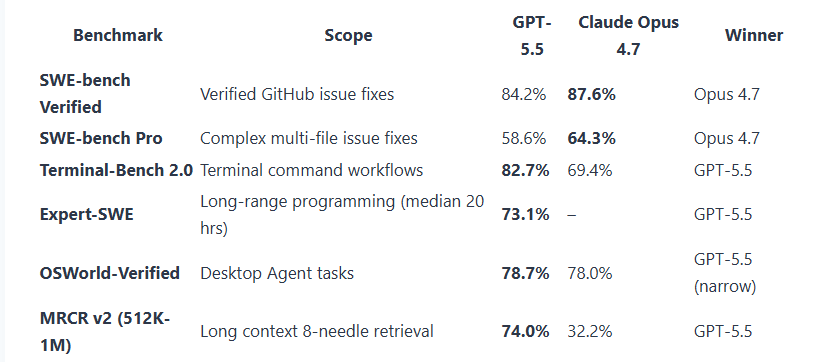
Les benchmarks sont unanimes, les deux outils proposent des performances similaires.
Et dans les faits, de plus en plus de techs les utilisent en tandem plutôt qu’en opposition. Qu’est-ce qu’on trouve chez l’un qu’on ne trouve pas chez l’autre ? Quelles sont les différences de Codex et Claude Code sur le plan technique ?
Gros projets et gestion du contexte : Claude Code tient sur la distance, Codex découpe le travail
Sur l’analyse architecturale profonde, Claude Code s’en sort nettement mieux. Sa fenêtre de contexte d’un million de tokens lui permet de garder l’ensemble d’un projet en tête, et le mécanisme des .claude_memory lui donne une forme de mémoire persistante entre les sessions. Les résultats sur SWE-bench Pro en témoignent.
C’est quoi les claude_memory ?
Ce sont de petits fichiers texte que Claude Code écrit lui-même dans votre projet. Il y consigne les décisions d’architecture, les conventions adoptées, les zones à ne pas toucher. À la session suivante, il les relit avant de commencer à travailler.
Pour autant, Claude Code est réputé instable sur les sessions longues. Si votre terminal se ferme ou que votre connexion SSH saute au milieu d’une tâche de 45 minutes, la session meurt. La commande claude –resume existe, mais l’IA recharge depuis le transcript plutôt que reprendre là où elle s’était arrêtée.
Côté Codex, la philosophie n’est pas la même : plutôt que de tout charger en mémoire, il découpe. Sur un projet trop massif, il dispatche plusieurs agents en parallèle sur des worktrees isolés, chacun chargé d’une portion du chantier. C’est efficace pour industrialiser, mais ça demande plus de supervision.
Son point faible sur les longues sessions : la compaction de contexte. Pour ne pas saturer sa mémoire, Codex résume périodiquement ce qui s’est passé plus tôt. Et ce résumé est parfois trop agressif. Au bout de plusieurs heures, l’agent peut souffrir d’une forme d’amnésie sélective : il réintroduit un bug qu’il avait pourtant corrigé deux heures avant.
Extensibilité : le MCP open-source face aux Codex Skills propriétaires
Claude Code repose sur le MCP (Model Context Protocol), un protocole open-source conçu pour brancher l’agent sur n’importe quelle source de données externe. Base de données, serveur interne, outil d’entreprise : si le connecteur existe, l’agent s’y branche proprement. L’interopérabilité est au cœur de l’architecture, mais pas au détriment de la sécurité.
Claude Code peut soudainement refuser de modifier un fichier ou d’exécuter une commande s’il détecte un mot-clé qu’il juge sensible, parfois à tort. C’est le revers de la politique stricte d’Anthropic sur ces sujets.
Codex a lui opté pour les Codex Skills : des scripts au format SKILL.md que l’on configure pour automatiser des actions répétitives (déploiement, migration de BDD, génération de documentation…). Plus propriétaire, mais aussi plus clé en main pour les équipes qui veulent industrialiser vite sans construire leur propre écosystème de connecteurs.
Transparence vs opacité : deux rapports au contrôle
Claude Code est bavard, et c’est assumé. Il explique ses plans, documente ses choix, demande confirmation avant chaque action potentiellement destructrice. Pour quelqu’un qui veut garder la main à chaque étape, c’est rassurant, mais plus chronophage.
Et la facture suit : chaque explication, chaque résumé d’étape, chaque demande de validation consomme des tokens. C’est son plus gros souci à l’usage intensif.
Codex lui, est plus direct, mais beaucoup moins transparent. Il expose bien les modèles disponibles (GPT-5.5, GPT-5.3-Codex-Spark…) et vous laisse en choisir un. Mais la logique de sélection automatique, elle, reste peu lisible : impossible de savoir facilement quel modèle a été appelé sur quelle tâche, ni quel impact ça a eu sur votre consommation de tokens. Un ticket ouvert sur le GitHub de Codex en avril 2026 demande précisément d’exposer ces informations dans l’interface, ce qui confirme que le sujet n’est pas encore réglé.
Comme Claude Code, en mode raisonnement maximal, il peut engloutir l’intégralité d’un quota de 5 heures en une seule session parce qu’il mouline en boucle sur un problème. Sauf qu’avec Codex, vous n’avez pas de visibilité claire sur ce qui a été consommé et pourquoi. Et contrairement à un Cursor, son UX reste très ancrée dans la logique CLI asynchrone : pas évident pour déboguer.
J’ai couvert beaucoup de terrain. Benchmarks, architecture, extensibilité, gestion du contexte, transparence, coûts. Si vous êtes arrivés jusqu’ici, vous avez probablement déjà une intuition sur lequel des deux correspond le mieux à votre façon de travailler. Mais avant de passer à mon avis, voici ce que ça donne en un coup d’œil :
| Critère | Codex | Claude Code |
|---|---|---|
| Interface | Desktop (macOS/Windows), web, CLI | CLI terminal pur |
| Approche de travail | Délégation asynchrone | Collaboration en direct |
| Gestion des gros projets | Multi-agents en parallèle (worktrees) | Fenêtre de contexte 1M tokens + .claude_memory et depuis peu, fonctionnement multi-agents |
| Extensibilité | Codex Skills (SKILL.md, propriétaire) | MCP (open-source) + commandes Claude semblables aux Skills |
| Transparence | Effet « boîte noire » | Explique chaque étape |
| Sessions longues | Compaction de contexte agressive | Instable si SSH/terminal coupe |
| Sécurité | Sandbox cloud permissive | Barrières strictes (peut freeze) |
| Consommation de tokens | Optimisée (72 % moins de tokens en sortie) | Élevée (bavardise) |
Codex ou Claude Code, c’est un débat qui enflamme Reddit, LinkedIn, Medium, Dev.to… Les threads se multiplient, les avis s’affrontent, les « je viens de switcher et je ne le regrette pas » côtoient les « Claude Code is not on the same level ». C’est un sujet. Voyons ce qui se dit.
Codex vs Claude Code : ce qui se dit sur Reddit
Sur r/codex et r/ClaudeCode, le débat fait rage. Tout le monde semble chercher sa team.
Certains ont des avis bien tranchés et jurent que Claude écrase Codex sur le codage pur, d’autres que Codex est sans concurrence pour le débogage et les refactorisations complexes. Mais ce qui ressort surtout, c’est que la plupart qui ont vraiment creusé les deux outils finissent par la même conclusion : ils ne choisissent pas.
« Je trouve que Claude peut faire des trucs complexes à 80% et ensuite j’utilise codex pour finir ce 20% », peut-on lire.
Ou encore : « Claude est plus rapide à exécuter une fois que le plan est clair, légèrement meilleur pour les refontes de fichiers multiples, et l’UX diff/edit dans le code de claude est plus agréable pour la révision. Codex est plus incisif sur les passages de raisonnement difficile (déboguer des bugs coriaces, planifier une refonte, révision de code). J’utilise Claude comme le cheval de travail et Codex comme l’avis secondaire quand Claude est bloqué ou sur le point de faire quelque chose de stupide. Si vous devez vraiment en choisir un pour 20 dollars : Claude Code pour le codage quotidien, Codex CLI sur un ChatGPT plus sub si vous en avez déjà un. Ils sont beaucoup plus proches que ne le laisse entendre le débat quotidien. »
« J’utilise beaucoup de Claude, assez peu de Codex » : le choix de JB Kempf
Dans la tech française, JB Kempf est une pointure. Fondateur de VLC, CTO de Scaleway, CEO de Kyber, fondateur et CTO de Playruo, co-animateur du podcast À la French. Rien que ça.Je l’ai reçu dans la Matinale Tech que j’anime tous les vendredis de 9h à 10h, et je lui ai posé la question directement : Claude Code ou Codex ?
Sa réponse, sans détour : « J’utilise beaucoup de Claude, assez peu de Codex, 0 de Copilot. »
Ensemble, on a parlé IA, souveraineté, jeux vidéos… Le replay est ici.
Mon avis : si je devais choisir, c’est Claude Code
Aujourd’hui, s’il faut en choisir un, je choisis Claude Code.
Anthropic a pris un virage fondamentalement différent d’OpenAI, et ça se voit dès la conception des modèles. OpenAI cherche à créer un modèle universel, capable de répondre à tout. Anthropic a entraîné Opus et Sonnet sur des problématiques d’entreprise, de développement et de complexité technique.
Exemple : la semaine dernière, j’ai demandé à Claude une recette de poulet. Raté, c’était trop cuit. Claude n’est pas fait pour ça. Mais pour aller en profondeur sur un sujet technique, obtenir une réponse dense, précise, qui ne survole pas, il n’a pas d’équivalent dans mon usage quotidien.
D’autant plus que mon domaine d’expertise est technique. Quand je pose une question à Claude, j’obtiens une réponse plus poussée techniquement, avec beaucoup plus de détails et un texte dense qui descend vraiment dans la profondeur du sujet. C’est exactement ce que je cherche au quotidien. Pour le poulet, je peux me débrouiller seul.
À titre d’exemple, voici comment j’utilise les outils Claude au quotidien :
Claude Desktop, pour la réflexion et la recherche : comprendre un sujet en profondeur, lancer des recherches en ligne poussées, analyser des articles, maîtriser une notion précise ou de la documentation technique.
Claude Code (CLI dans le terminal), pour l’opérationnel : tout mon développement, la gestion de mes notes, ma to-do liste, mon calendrier. D’ailleurs, je donne un webinaire à ce sujet le 18 juin à 12h.

Pour conclure, et répondre à la question « Faut-il vraiment choisir sa team ?’ », je dirais qu’il n’y a pas de champion universel mais des outils qui correspondent à une façon de travailler plutôt qu’une autre.
Je vous recommande Claude Code si vous êtes un développeur qui vit dans son terminal, qui veut la meilleure qualité de code possible sur des architectures complexes, qui préfère collaborer étape par étape plutôt que déléguer à l’aveugle, et qui peut absorber une facture API plus salée en échange d’un contrôle fin.
Je vous recommande Codex si vous devez faire tourner de gros chantiers en parallèle (multi-agent), automatiser des tâches système lourdes, déléguer des refactorisations en arrière-plan pendant que l’équipe avance sur d’autres fronts, ou si vous cherchez à bâtir des flows adversariaux où les deux modèles se challengent mutuellement.
La course est loin d’être terminée. Les deux équipes remettent l’ouvrage sur le métier à un rythme frénétique, et dans six mois, ce comparatif aura sans doute besoin d’une mise à jour.
Méfait accompli.
À explorer dans le grimoire

Kubernetes AI Gateway : pourquoi Kubernetes va devenir la référence pour gérer les modèles d’IA ?

Hausse du prix de la RAM : pourquoi les prix du Cloud vont aussi augmenter
