Cilium : la technologie qui a séduit les DevOps et les GAFAM en 2025

Amazon, Google, Microsoft… Les GAFAM ont adopté Cilium. Et il suffit de parcourir trois threads DevOps pour constater que la technologie fait aussi l’unanimité auprès des équipes d’infrastructure. Gains de coûts, performance, observabilité : cette brique réseau pensée pour Kubernetes coche toutes les cases. Pourquoi un tel engouement ? Quel impact concret sur votre architecture ? Et comment se positionne Cilium face à Istio ou Linkerd ? Décryptage complet et benchmark. Place à la magie.

Resumulus : les 3 points à retenir de l’article
- Cilium est une solution de mise en réseau qui déplace la logique réseau dans le kernel via eBPF, ce qui simplifie et accélère le networking Kubernetes.
- Son interface de visualisation Hubble apporte une visibilité fine sur les flux que les solutions traditionnelles peinent à offrir.
- Cilium se distingue de Linkerd et Istio par son architecture eBPF, plus moderne et plus efficace à grande échelle. Avec la fin d’Ingress NGINX Controller, il sera encore plus pertinent.
Si les GAFAM ont misé sur Cilium, ce n’est pas uniquement pour affiner leur réseau.
Derrière l’optimisation technique se cache souvent un effet de levier financier.
Prenons l’exemple de Facebook.
En 2010, l’application repose toujours sur PHP et se heurte à des problèmes de performance… qui coûtent une fortune. Réécrire des millions de lignes de code ou remplacer toute l’équipe ? Impensable. La solution sera donc technique : Facebook crée HHVM (HipHop Virtual Machine), une réimplémentation complète du moteur d’exécution PHP.
À la clé : +60 % de performances sur l’interprétation du bytecode, et des millions d’euros d’infrastructure économisés.
Un parallèle qui peut s’appliquer à notre sujet du jour : Cilium ne remplace pas Kubernetes, mais en réinvente une composante critique : la couche réseau. Exactement comme HHVM a redonné un second souffle à PHP chez Facebook.
Solution technique avec un impact réel : la poulie pour soulever une charge.
Cilium est une solution de mise en réseau, de sécurité et d’observabilité open source pour les environnements conteneurisés.
Elle se base sur eBPF (extended Berkeley Packet Filter), une technologie du noyau Linux qui permet d’exécuter du code personnalisé sans modifier le kernel ni multiplier les couches intermédiaires.
Parce qu’il opère très bas dans la pile réseau, Cilium peut :
- orchestrer les communications entre les pods
- appliquer des politiques de sécurité dynamiques
- offrir une observabilité précise, en temps réel
En clair : Cilium est le système nerveux de votre cluster Kubernetes, celui qui fait circuler l’information vite, proprement et en toute sécurité.
Moins de cycles CPU, moins de coûts
Cilium réduit à la fois les coûts opérationnels et les coûts d’infrastructure.
Sur AWS, par exemple, il supprime les limites d’adresses IP par nœud, ce qui augmente la densité et réduit le nombre d’instances nécessaires.
Avec l’IP Delegation CNI, vous pouvez faire tourner bien plus de pods sur un même nœud.
Même une commande comme kubectl create deployment nginx –image nginx –replicas 200 fonctionne sur un cluster de seulement 2 nœuds.
Moins de nœuds, une facture cloud plus légère.
Côté CPU, certains gains sont spectaculaires.
Exemple avec Seznam, un moteur de recherche tchèque : en remplaçant leur ancien load-balancer IPVS (IP Virtual Server, load-balancer L4 du noyau Linux) par celui de Cilium (L4 aussi),ils ont divisé par 72 leur utilisation de CPU.
Pas besoin de vous faire un dessin. Si ? Le voici :
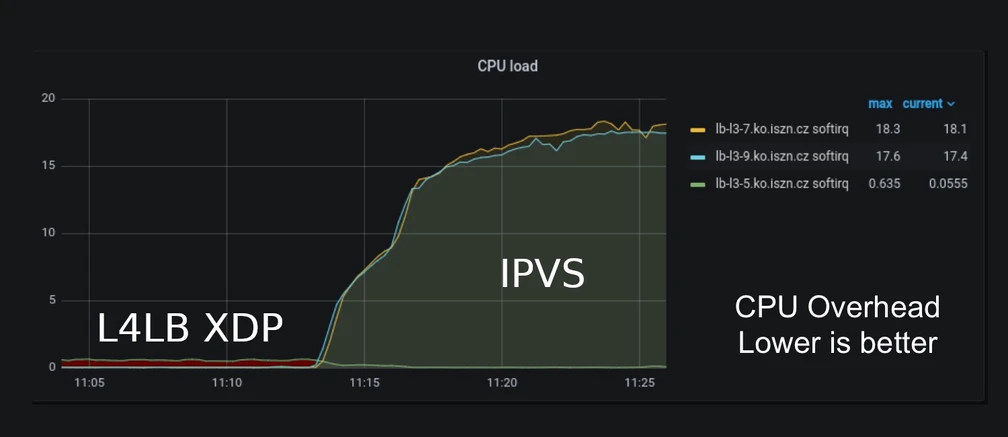
Utilisation CPU load-balancer Cilium (L4LB XDP) vs. load-balancer IPVS utilisé initialement
(Cilium Standalone Layer 4 Load Balancer XDP, Ondrej Blazek, Infrastructure Engineer @ Seznam.cz)
Evidemment, les résultats dépendent de l’infra d’origine et de votre activité. Plus votre infra est petite, plus les gains seront modestes.
Cerise sur le gâteau : le mode sans kube-proxy supprime un composant entier de l’infrastructure et exploite eBPF pour améliorer encore plus la performance.
Performance : jusqu’à 30 % de latence réseau en moins
Là où eBPF devient magique, c’est qu’il exécute directement le code dans le kernel.
En d’autres mots : pas de transition vers l’espace utilisateur → moins d’allers-retours → moins de latence.
Ici, on parle de 30 % de latence réseau en moins par rapport aux solutions traditionnelles. Un effet qui se voit surtout à grande échelle, où chaque milliseconde économisée compte.
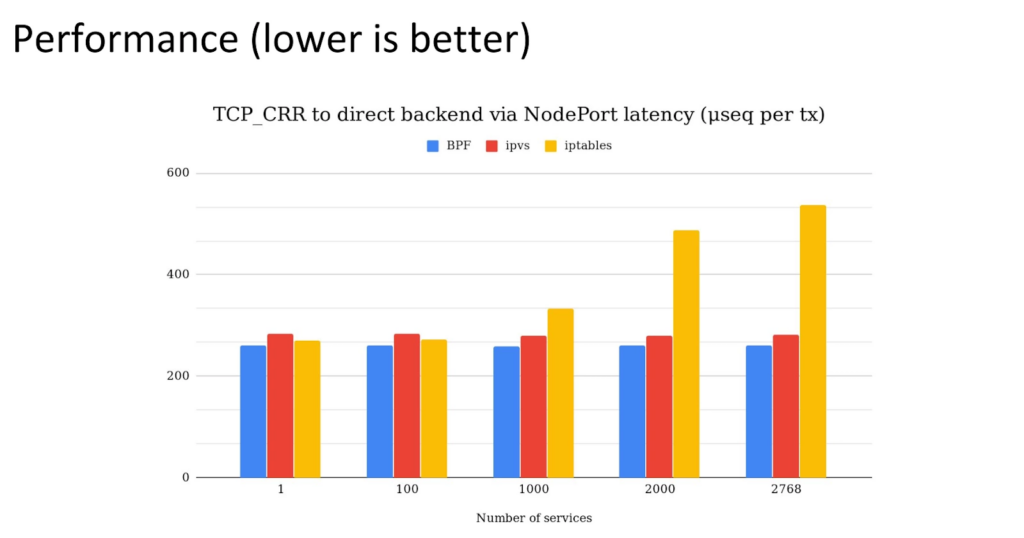
Benchmark de latence réseau (plus c’est bas, mieux c’est).
Source : Isovalent – What is Kube-Proxy and why move from iptables to eBPF? Jeremy Colvin
Observabilité : Cilium met le paquet avec Hubble
C’est sur la visibilité réseau que Cilium bluffe tout le monde.
Cilium fonctionne avec Hubble, son interface de visualisation qui génère automatiquement une carte visuelle de tous vos services et de leurs connexions.
Vous voyez non seulement que deux services communiquent, mais aussi quelles API sont utilisées. Un niveau de détail précieux pour résoudre des problèmes complexes. DNS, HTTP, gRPC… Tout y est.
Si vous avez déjà eu à gérer une app en micro-services, vous savez que le réseau, c’est ce qu’il y a de plus difficile à déboguer. C’est instable, critique et Cilium vient rassurer et donner de la visibilité.
Les journaux de flux capturent l’intégralité du trafic : IP source/destination, ports, et même le verdict (autorisé/refusé). C’est comme un tcpdump, mais en plus facile à utiliser.
Ces fonctionnalités évitent des heures de débogage. Et vous en serez encore plus contents si vous devez passer la certification SOC2.
Nous avons par exemple détecté grâce à Hubble qu’un de nos services se faisait “DDOS” par un autre. Un autre exemple : suite à une erreur en production, nous avons dû capturer les requêtes réseau avec Hubble et les exporter. Après les avoir triées, nous les avons rejouées sur l’environnement de test. Sans Cilium, ça n’aurait pas été possible.
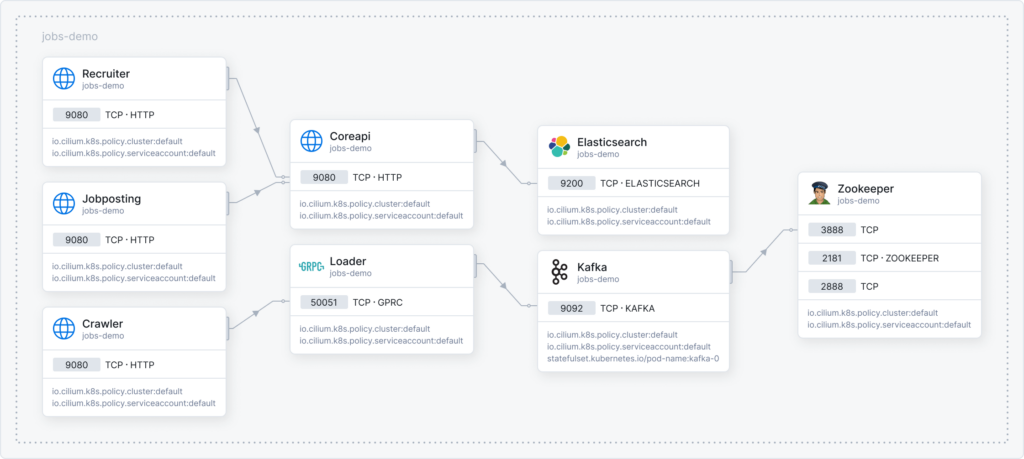
Graph de dépendances de services dans Hubble. Source : Cilium.io
Sécurité : des politiques de contrôle d’accès fines
La sécurité est une priorité absolue, surtout dans des environnements cloud natifs complexes.
Plutôt que de s’appuyer sur des IP qui changent à chaque redémarrage de pod, Cilium utilise les identités de services pour appliquer des politiques de sécurité qui restent cohérentes, même lorsque les pods sont recréés avec de nouvelles adresses IP.
L’identité de service repose sur des attributs tels que des labels : une façon d’identifier les ressources d’infrastructure de manière durable et cohérente.
L’outil permet notamment d’appliquer le principe du moindre privilège et Zero Trust en contrôlant précisément les communications inter-services. Résultat : moins de surface d’attaque et un respect des normes SOC2 ou ISO 27001.
Enfin, Cilium protège à différents niveaux du trafic réseau : de la couche 3-4 (IP/Port) jusqu’à la couche 7 (HTTP, gRPC, Kafka). Il bloque les attaques au niveau des API. Des fonctionnalités à croiser avec celles d’Hubble qui donne une visibilité sur le trafic sortant d’un coup d’œil pour repérer un potentiel hacker connecté.

Pour comprendre ce qui distingue Cilium de Linkerd ou d’Istio Ambient Mode, il faut considérer deux choses :
- La philosophie et l’architecture technique de chaque technologie
- Leur comportement mesuré en benchmark
Architectures et philosophies : trois approches très différentes
Linkerd, Istio Ambient Mode et Cilium ne reposent pas sur les mêmes choix techniques.
Et ces choix influencent directement les coûts, la latence et la consommation CPU.
Dans un service mesh, le proxy est le cœur du réacteur. Il intercepte, analyse et gère le trafic.
Deux grandes familles existent :
- Proxies L4 (IP + ports) → rapides, légers
- Proxies L7 (HTTP, gRPC, Kafka) → précis, mais gourmands
Plus on monte dans la pile réseau, plus c’est puissant… mais plus ça consomme CPU.
Comprendre cette différence, c’est comprendre pourquoi certains choix technologiques peuvent faire exploser une facture cloud ou alourdir drastiquement la latence.
Maintenant que ce point est clarifié, comparons les philosophies.
Linkerd : léger, rapide mais un modèle commercial piégeux
Linkerd mise sur la sobriété. Son proxy, écrit en Rust, est extrêmement économe en mémoire. Il fonctionne principalement comme un proxy L4, avec quelques capacités L7 minimales.
C’est ce choix architectural qui explique ses performances élevées dans les benchmarks (voir ci-après) : peu d’interceptions, peu d’analyse, donc peu de CPU consommé.
Sur le papier, c’est séduisant.
Mais la réalité commerciale l’est beaucoup moins :
- la version gratuite (“edge”) n’est pas destinée à la production,
- la version “stable” est désormais payante.
En bref, vous développez gratuitement, puis au moment du go live… vous devez passer à la caisse.
Pour un composant aussi critique, c’est un pari dangereux.
Notre âme de FinOps ne vous conseille pas de vous lancer là-dedans.
À moins d’être déjà sur Linkerd, il n’y a pas de raison solide d’y migrer aujourd’hui.
Istio : un modèle historique qui se réinvente avec l’Ambiant Mode
Istio a longtemps trainé un handicap majeur : un sidecar Envoy (L7) dans chaque pod.
Symbole d’une architecture élégante, mais coûteuse.
Avec Istio Ambient Mode, le projet corrige sa plus grande faiblesse. Désormais :
- ztunnel gère le trafic en L4, de manière légère et rapide
- waypoint traite le L7, mais uniquement lorsque nécessaire
Autrement dit : Istio devient modulable.
On active la lourdeur L7 seulement quand on en a besoin.
Un vrai tournant dans son histoire.
Cilium : l’approche eBPF, une autre dimension
Cilium n’est pas un mesh “à l’ancienne”. Il retire des couches au lieu d’en ajouter.
Concrètement, grâce à eBPF:
- la couche L4 est exécutée directement dans le noyau Linux, sans proxy user-space,
- la couche L7 s’appuie sur Envoy, mais seulement si vous activez des fonctionnalités L7 (HTTP policies, gRPC, etc.).
C’est la seule technologie du trio à déporter la logique réseau dans le kernel, ce qui veut dire : moins de latence, moins de consommation CPU, moins de composants à opérer.
Cilium agit à la racine du réseau Kubernetes, là où Linkerd et Istio ajoutent des couches au-dessus. C’est une philosophie entièrement différente.
Cilium, Linkerd, Istio : un benchmark vaut plus que mille mots
Maintenant que les philosophies et les architectures sont claires, les benchmarks de LiveWyer prennent tout leur sens. Ils montrent très concrètement comment les choix techniques de chaque mesh se traduisent en latence, en overhead CPU et en efficacité globale 👇
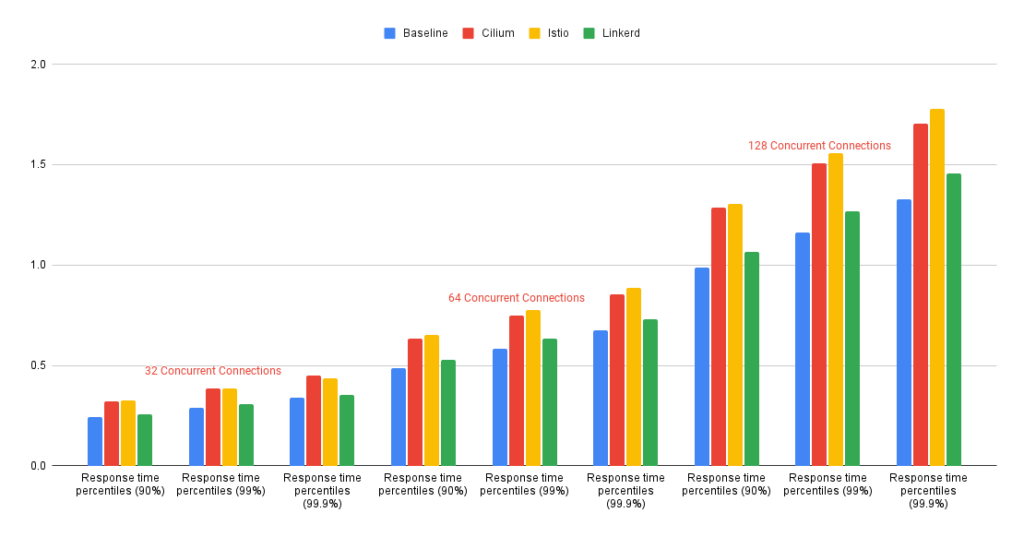
Internal Communications Test Results Diagram
Source : LiveWyer, Service Meshes Decoded Part One: A performance comparison of Istio vs Linkerd vs Cilium, Oleksandr.
External Communications Test Results Diagram
Source : LiveWyer, Service Meshes Decoded Part One: A performance comparison of Istio vs Linkerd vs Cilium, Oleksandr.
Linkerd : le plus rapide… mais avec une zone d’ombre
Linkerd ressort comme le mesh le plus rapide du groupe : seulement 5 à 10 % de ralentissement par rapport à un cluster sans mesh. Très certainement grâce à son proxy Rust très léger, qui agit comme un L4 optimisé, Linkerd introduit très peu de surcharge. Ses sidecars consomment peu de ressources, ce qui se traduit mécaniquement par de meilleurs temps de réponse.
Mais il y a un hic. Et pas des moindres. Pour le trafic externe, Linkerd dépend totalement des Ingress Controllers. Cela signifie que si votre ingress est gourmand, instable ou mal configuré, vous perdez une partie de ce gain. À l’inverse, Cilium et Istio Ambient Mode gèrent leur propre trafic externe, ce qui rend leur performance plus prévisible dans des environnements complexes.
Istio Ambient Mode : le meilleur contrôleur d’entrée
Istio affiche un ralentissement de 25 à 35 % par rapport à la référence.
Ses sidecars Envoy, plus gourmands que ceux de Linkerd, introduisent un overhead notable. Rien de surprenant : Istio Ambient Mode travaille beaucoup plus en L7, avec un contrôle fin des requêtes et de la politique applicative.
Mais il faut noter un point souvent sous-estimé : Istio Ambient Mode possède le meilleur contrôleur d’entrée du comparatif.
Autrement dit :
- Il peut supporter de fortes charges en entrée.
- Il optimise très bien les ressources associées au trafic externe.
- Il offre une performance plus stable sur les entrées HTTP/HTTPS complexes.
Dans des environnements où le trafic en entrée est critique, cela peut devenir un avantage réel.
Cilium : le plus robuste en conditions réelles
Cilium affiche des résultats intermédiaires :
- Il peut 20 à 30 % de ralentissement pour les communications internes
- 30 à 40 % pour les communications externes.
Sur le papier, cela peut sembler légèrement moins bon.
Mais il faut regarder ce que les chiffres disent réellement :
- son plan de données L4 est exécuté dans le kernel via eBPF,
- il gère extrêmement bien les scénarios à grand nombre de connexions.
LiveWyer indique que d’autres solutions offrent plus de requêtes par seconde dans certains tests, mais Cilium se démarque par sa stabilité et sa capacité à absorber des charges très élevées sans s’effondrer.
C’est la différence entre “le plus rapide sur un benchmark” et “le plus robuste dans une architecture réelle.”
Synthèse du benchmark Cilium VS Linkerd VS Istio
👉 Si votre priorité numéro 1 est la vitesse brute, Linkerd domine les tests.
👉 Si vous cherchez un mesh L7 très complet, Istio Ambient Mode offre la meilleure finesse de contrôle et le meilleur contrôleur d’entrée.
👉 Si vous opérez un cluster large, dynamique, avec beaucoup de trafic interne, Cilium offre un excellent compromis performance / scalabilité / simplicité opérationnelle, un terrain où il excelle.
Ces différences de performance, même de quelques pourcentages, peuvent représenter des économies substantielles sur une architecture Kubernetes qui tourne 24h/24 sur des centaines de nœuds.
Pérennité : qui sera encore là dans 5 ans ?
Lorsqu’on choisit un service mesh ou une brique réseau critique, la question des performances est centrale. Mais elle ne suffit pas. Il faut aussi avoir des garanties solides sur la maintenabilité, la stabilité du projet et sa fiabilité dans le temps, parce qu’un composant clé du réseau ne se remplace pas tous les six mois.
Linkerd : une trajectoire commerciale qui inquiète
La décision de réserver les versions “stables” aux offres payantes est un signal d’alerte pour toutes les équipes qui recherchent une technologie durable, gratuite et réellement open source.
Ce modèle pose une question simple : que se passe-t-il si l’éditeur change encore ses conditions commerciales ?
Dans un composant aussi critique que le réseau, cette incertitude refroidit légitimement les organisations.
Istio : un projet solide, soutenu, et capable d’évoluer
Istio bénéficie d’un soutien massif : Google d’un côté, la CNCF de l’autre.
Le projet ne risque pas de disparaître. Mieux : l’arrivée d’Ambient Mode prouve sa capacité à remettre en question ses choix historiques, y compris l’un de ses symboles, les sidecars Envoy omniprésents.
En abandonnant progressivement ce modèle au profit d’une architecture L4/L7 plus fine, Istio Ambient Mode montre qu’il sait évoluer pour réduire les coûts et s’adapter aux nouveaux paradigmes du Cloud moderne. (Et oui : ciao les sidecars 👋)
Cilium : une montée en puissance continue
Cilium, désormais projet gradué de la CNCF, accumule les signes de maturité :
- adoption rapide par les acteurs cloud,
- intégration native avec Kubernetes,
- philosophie eBPF en ligne avec la direction du kernel Linux,
- contribution active à SIG-Network.
Tout indique que Cilium est l’un des paris les plus sûrs pour le long terme. Non seulement le projet reste très actif, mais il s’inscrit dans une tendance profonde du cloud moderne : déplacer l’intelligence réseau dans le kernel et simplifier le plan de données.
Cilium n’a pas conquis les GAFAM par accident.
Il s’est imposé parce qu’il touche au cœur battant de Kubernetes : son réseau.
Là où d’autres multiplient les couches et les proxies, Cilium allège, clarifie et accélère. Là où les mesh historiques saturent le CPU, Cilium s’installe dans le kernel et change les règles du jeu. Là où le débogage réseau ressemble habituellement à un voyage dans l’obscurité, Hubble allume les lanternes.
Ce n’est pas la solution la plus rapide en laboratoire.
Mais c’est celle qui tient debout quand l’infrastructure devient une hydre de centaines de nœuds.
Celle qui reste lisible, stable et prédictible quand le trafic explose.
Celle qui repose sur eBPF, une technologie soutenue par les géants du Linux et par l’avenir du kernel.
Bon vous l’aurez compris, on est fans ici.
Méfait accompli.
FAQ Cilium
Cilium est une solution de networking, sécurité et observabilité pour Kubernetes, basée sur eBPF. Elle remplace une partie de la logique réseau traditionnelle par du code exécuté directement dans le kernel Linux.
Oui. Cilium est un projet gradué CNCF, largement adopté par les cloud providers et utilisé en production par de grands acteurs.
Oui. Cilium s’appuie sur eBPF, qui nécessite un kernel Linux moderne (version exacte dépendante des fonctionnalités activées).
C’est un point à valider avant migration.
Cilium réduit surtout la consommation CPU, améliore parfois la latence, et permet une meilleure densité de pods grâce à eBPF.
Il n’est pas le plus rapide en vitesse brute, mais offre un meilleur équilibre global pour les clusters de grande taille.
Oui. Le mode kube-proxy replacement est stable et utilisé en production.
Il réduit la complexité de la pile réseau et améliore parfois les performances.
Partiellement. Cilium fournit un mesh léger (L3/L4/L7), suffisant pour de nombreux cas.
Pour des besoins L7 avancés, Istio reste plus complet.
Oui. Les policies réseau basées sur l’identité, la visibilité des flux et la granularité L3→L7 facilitent l’audit, le contrôle des communications et les exigences de traçabilité.
Oui. Cilium propose des capacités de Cluster Mesh, BGP, egress control et s’intègre avec AKS, EKS et GKE selon les versions.
La migration est généralement simple, mais dépend de :
-
l’état du cluster,
-
la présence ou non d’un service mesh existant,
-
et du kernel.
Il est recommandé de tester en environnement de staging avant bascule.
Oui, dans la plupart des cas.
Cilium propose une implémentation Gateway API native (basée sur Envoy) qui peut remplacer progressivement NGINX Ingress Controller.
L’approche est plus moderne, mieux intégrée à Kubernetes et évite les limites historiques des annotations NGINX. Plus de détails dans cet article.
À explorer dans le grimoire

Images Bitnami : ce qui va changer fin août et comment anticiper la transition

Fin d’Ingress NGINX Controller : ce que vous devez faire avant mars 2026

Erreur Kubernetes “short name mode is enforcing” : voici pourquoi vos Pods ne démarrent plus